How to use the CLI
This document will guide you through the usage of Zeblok cli
CLI Usability and commands.
Show-URL
This command just outputs the APP URL and datalake Url configured in zeblok configure command
zeblok showUrlSnapshot
This command is used to create snapshot of your workstation on which it creates a docker image whose tag is emailed to the user on which that tag can be used to create a new workstation with current configuration
zeblok snapshot
? Enter the name for docker file getting generated : <Docker Image Name>
? Select your DataLake Bucket to Deploy (Use arrow keys) <Minio Bucket Selection>Brief
Snapshot command copy all the files from your notebook with the same structure as in current one with that it also creates requirments.txt with all the installed packages in your current notebook and installs it when you spawn the new workstation with that docker image to have same configuration as you have currently .
requirments.txt is generated automatically with
pip list --format=freezeBase image for workstation used is
minimal-notebook:2023.09.20
Components
Docker Image Name- The image name you want the docker to haveMinio Bucket Selection- Select the bucket where you want to store all the data of your notebook
Openvino
This command is used to serve model using openvino
Components
IR_OUTPUT_PATH- Folder containing the <IR_OUTPUT_NAME>.xml and the <IR_OUTPUT_NAME>.binIR_OUTPUT_NAME- IR output name which is same for both .xml and .bin file in theIR_OUTPUT_PATHBUCKET_NAME- Select the bucket where you want to store the model filesAUTO_DEPLOY- This is Boolean Input which defines if you want to deploy the model directly to AI-APINAMESPACE- Namespace where the ai api to be deployed and asked ifAUTO_DEPLOYis marked asYESDATACENTER- Datacenter where the ai api to be deployed and asked ifAUTO_DEPLOYis marked asYESKISOK- Kisoks where the ai api to be deployed and asked ifAUTO_DEPLOYis marked asYESPLAN- Plan in which the ai api to be deployed and asked ifAUTO_DEPLOYis marked asYESDEPLOYMENT_NAME- Name of deployment used to deploy AI-API and asked ifAUTO_DEPLOYis marked asYES
Ideal File Structure
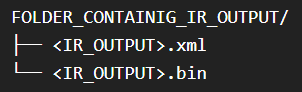
For openvino model serving to work the output path must contain 2 files with same name with extensions *.xml and *.bin
Bentoml
Bentolml model serving serves a bentoml model served built using bentoml build command . It fetches the model with bentoml list --output json command and lists one which you want to serve .
Components
MODEL_NAME- Select the model built using the bentoml build commandbentoml buildBUCKET_NAME- Select the bucket where you want to store the model filesAUTO_DEPLOY- This is Boolean Input which defines if you want to deploy the model directly to AI-APINAMESPACE- Namespace where the ai api to be deployed and asked ifAUTO_DEPLOYis marked asYESDATACENTER- Datacenter where the ai api to be deployed and asked ifAUTO_DEPLOYis marked asYESKISOK- Kisoks where the ai api to be deployed and asked ifAUTO_DEPLOYis marked asYESPLAN- Plan in which the ai api to be deployed and asked ifAUTO_DEPLOYis marked asYESDEPLOYMENT_NAME- Name of deployment used to deploy AI-API and asked ifAUTO_DEPLOYis marked asYES
The model serving of bentoml needs bentoml installed on your workstation
If there is no model to select in first question then try running
bentoml buildin the model creation .
Mlflow
Mlflow model serving uses two process to serve a model first is to get model into your directory and second one is to serve that model
Commands
1. Get model
To get a model from mlflow register use command
Components
MLFLOW_TRACKING_URL- Mlflow tracking URL where your model is stored to .RUN_ID- Run id of the model you are willing to serve
To create a new mlflow microservice please refer to documentation of AI-Microcloud .
2. Serve Model
Once the command To get the model is done you will need to run modelserve command to serve model
Components
DOWNLOADED_MODEL_PATH- Enter folder name where your model is stored .IR_OUTPUT_NAME- Enter any name that you want to put for model .AUTO_DEPLOY- This is Boolean Input which defines if you want to deploy the model directly to AI-APINAMESPACE- Namespace where the ai api to be deployed and asked ifAUTO_DEPLOYis marked asYESDATACENTER- Datacenter where the ai api to be deployed and asked ifAUTO_DEPLOYis marked asYESKISOK- Kisoks where the ai api to be deployed and asked ifAUTO_DEPLOYis marked asYESPLAN- Plan in which the ai api to be deployed and asked ifAUTO_DEPLOYis marked asYESDEPLOYMENT_NAME- Name of deployment used to deploy AI-API and asked ifAUTO_DEPLOYis marked asYES
The model serving of mlflow needs mlflow installed on your workstation
LLAMA
This command serves LLAMA model with CPP serving .
Components
IR_OUTPUT_PATH- Enter the path where your model andrequirements.txtfile is situated .IR_OUTPUT_NAME- Enter the model name with its extension whether its .gguml or .ggufBUCKET_NAME- Select the bucket where you want to store the model filesAUTO_DEPLOY- This is Boolean Input which defines if you want to deploy the model directly to AI-APINAMESPACE- Namespace where the ai api to be deployed and asked ifAUTO_DEPLOYis marked asYESDATACENTER- Datacenter where the ai api to be deployed and asked ifAUTO_DEPLOYis marked asYESKISOK- Kisoks where the ai api to be deployed and asked ifAUTO_DEPLOYis marked asYESPLAN- Plan in which the ai api to be deployed and asked ifAUTO_DEPLOYis marked asYESDEPLOYMENT_NAME- Name of deployment used to deploy AI-API and asked ifAUTO_DEPLOYis marked asYES
IR_OUTPUT_PATHmust contain the model andrequirements.txtfile to workMake sure you enter
IR_OUTPUT_NAMEwith its extension .Depending on the size of model it will take time around 2 to 3 hours
VLLM
This command serves model with Vllm model serving .
Components
MODEL_DIRECTORY- Enter the folder name where your model and files are situated inside the workstation .BUCKET_NAME- Select the bucket where you want to store the model filesAUTO_DEPLOY- This is Boolean Input which defines if you want to deploy the model directly to AI-APINAMESPACE- Namespace where the ai api to be deployed and asked ifAUTO_DEPLOYis marked asYESDATACENTER- Datacenter where the ai api to be deployed and asked ifAUTO_DEPLOYis marked asYESKISOK- Kisoks where the ai api to be deployed and asked ifAUTO_DEPLOYis marked asYESPLAN- Plan in which the ai api to be deployed and asked ifAUTO_DEPLOYis marked asYESDEPLOYMENT_NAME- Name of deployment used to deploy AI-API and asked ifAUTO_DEPLOYis marked asYES
Make sure
MODEL_DIRECTORYyou enter contains all the files related to model .Depending on the size of model it will take time around 1 to 2 hours